Let’s kick things off with a chapter on the basics.
Specifically, in this chapter, I’m going to cover why technical SEO is still SUPER important in 2024.
I’ll also show you what is (and isn’t) considered “technical SEO”.
Let’s dive in.
What Is Technical SEO?
Technical SEO is the process of ensuring that a website meets the technical requirements of modern search engines with the goal of improved organic rankings. Important elements of technical SEO include crawling, indexing, rendering, and website architecture.
Why Is Technical SEO Important?
You can have the best site with the best content.
But if your technical SEO is messed up?
Then you’re not going to rank.
At the most basic level, Google and other search engines need to be able to find, crawl, render and index the pages on your website.
But that’s just scratching the surface. Even if Google DOES index all of your site’s content, that doesn’t mean your job is done.
That’s because, for your site to be fully optimized for technical SEO, your site’s pages need to be secure, mobile optimized, free of duplicate content, fast-loading… and a thousand other things that go into technical optimization.
That’s not to say that your technical SEO has to be perfect to rank. It doesn’t.
But the easier you make it for Google to access your content, the better chance you have to rank.
How Can You Improve Your Technical SEO?
Like I said, “Technical SEO” isn’t just crawling and indexing.
To improve your site’s technical optimization, you need to take into account:
Fortunately, I’m going to cover all of those things (and more) in the rest of this guide.
Chapter 2:Site Structure and Navigation
In my opinion, your site’s structure is “step #1” of any technical SEO campaign.
(Yes, even coming before crawling and indexing)
Why?
First off, many crawling and indexing issues happen because of poorly-designed site structure. So if you get this step right you don’t need to worry as much about Google indexing all of your site’s pages.
Second, your site structure influences everything else you do to optimize your site… from URLs to your sitemap to using robots.txt to block search engines from certain pages.
The bottom line here is this: a strong structure makes every other technical SEO task MUCH easier.
With that, let’s get into the steps.
Use a Flat, Organized Site Structure
Your site structure is how all of the pages on your website are organized.
In general, you want a structure that’s “flat”. In other words: your site’s pages should all be only a few links away from one another.
Why is this important?
A flat structure makes it easy for Google and other search engines to crawl 100% of your site’s pages.
This isn’t a big deal for a blog or local pizza shop website. But for an ecommerce site with 250k product pages? A flat architecture is a BIG deal.
You also want your structure to be super organized.
In other words, you don’t want a site architecture like this:
This messy structure usually creates “orphan pages” (pages without any internal links pointing to them).
It also makes it hard to ID and fix indexing issues.
You can use the Semrush “Site Audit” feature to get a bird’s eye view of your site structure.
This is helpful. But it’s not super visual.
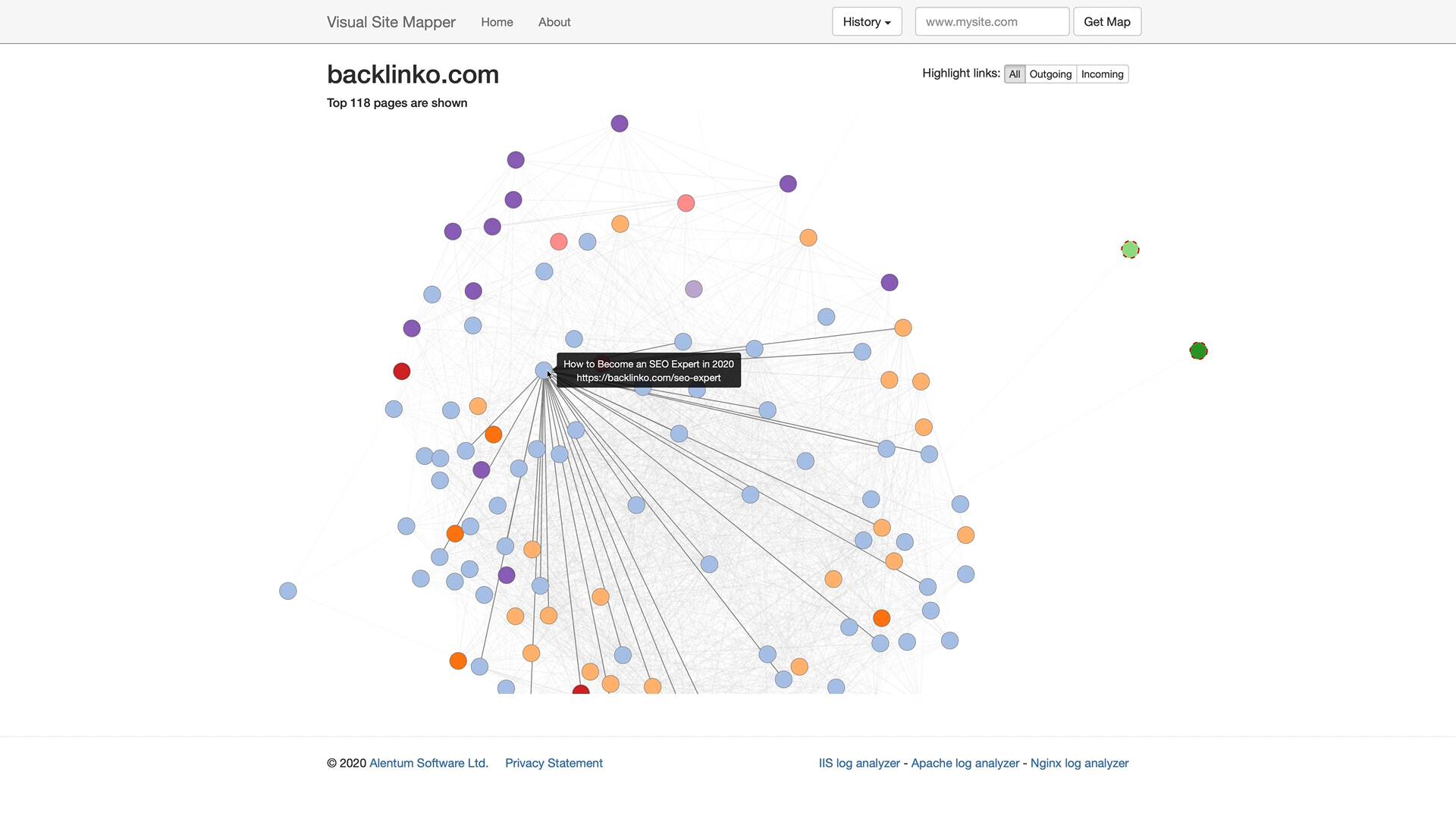
To get a more visual look at how your pages are linked together, check out Visual Site Mapper.
It’s a free tool that gives you an interactive look at your site’s architecture.
Consistent URL Structure
There’s no need to overthink your URL structure. Especially if you run a small site (like a blog).
That said: you do want your URLs to follow a consistent, logical structure. This actually helps users understand “where” they are on your site.
For example, the pages on our SEO Marketing Hub all include the “/hub/seo” subfolder to help Google know that all of these pages are under the “SEO Marketing Hub” category.
Which seems to work. If you Google “SEO Marketing Hub”, you’ll notice that Google adds sitelinks to the results.
As you might expect, all of the pages linked to from these sitelinks are inside of the hub.
What I like most about this feature is that you get info on your site’s overall technical SEO health.
Site performance report.
And issues with your site’s HTML tags.
Each of these 3 tools have their pros and cons. So if you run a large site with 10k+ pages, I recommend using all three of these approaches. That way, nothing falls through the cracks.
Internal Link to “Deep” Pages
Most people don’t have any issues getting their homepage indexed.
It’s those deep pages (pages that are several links from the homepage) that tend to cause problems.
A flat architecture usually prevents this issue from happening in the first place. After all, your “deepest” page will only be 3-4 clicks from your homepage.
Either way, if there’s a specific deep page or set of pages that you want indexed, nothing beats a good old-fashioned internal link to that page.
Especially if the page you’re linking from has a lot of authority and gets crawled all the time.
Use an XML Sitemap
In this age of mobile-first indexing and AMP does Google still need an XML sitemap to find your site’s URLs?
Yup.
In fact, a Google rep recently stated that XML sitemaps are the “second most important source” for finding URLs.
(The first? They didn’t say. But I’m assuming external and internal links).
If you want to double check that your sitemap is all good, head over to the “Sitemaps” feature in the Search Console.
This will show you the sitemap Google is seeing for your site.
GSC “Inspect”
Is a URL on your site not getting indexed?
Well, the GSC’s Inspect feature can help you get to the bottom of things.
Not only will it tell you why a page isn’t getting indexed…
But for pages that ARE indexed, you can see how Google renders the page.
That way, you can double check that Google is able to crawl and index 100% of the content on that page.
Chapter 4:Thin and Duplicate Content
If you write unique, original content for every page on your site then you probably don’t need to worry about duplicate content.
That said:
Duplicate content can technically crop up on any site… especially if your CMS created multiple versions of the same page on different URLs.
And it’s the same story with thin content: it’s not an issue for most websites. But it can hurt your overall site’s rankings. So it’s worth finding and fixing.
And in this chapter I’m going to show you how to proactively fix duplicate and thin content issues on your site.
Use an SEO Audit Tool to Find Duplicate Content
There are two tools that do a GREAT job at finding duplicate and thin content.
It scans your site for duplicate content (or thin content). And lets you know which pages need to be updated.
The Semrush site audit tool also has a “Content Quality” section that shows you if your site has the same content on several different pages.
That said:
These tools focus on duplicate content on your own website.
“Duplicate content” also covers pages that copy content from other sites.
To double-check that your site’s content is unique, I recommend Copyscape’s “Batch Search” feature.
Here’s where you upload a list of URLs and see where that content appears around the web.
If you find a snippet of text that shows up on another site, search for that text in quotes.
If Google shows your page first in the results, they consider you the original author of that page.
And you’re good to go.
Note: If other people copy your content and put it on their website, that’s their duplicate content problem. Not yours. You only need to worry about content on your site that’s copied (or super similar) to content from other websites.
Noindex Pages That Don’t Have Unique Content
Most sites are going to have pages with some duplicate content.
And that’s OK.
This becomes a problem when those duplicate content pages are indexed.
The noindex tag tells Google and other search engines to not index the page.
You can double check that your noindex tag is set up correctly using the “Inspect URL feature” in the GSC.
Pop in your URL and click “Test Live URL”.
If Google is still indexing the page, you’ll see a “URL is available to Google” message. Which means that your noindex tag isn’t set up correctly.
But if you see an “Excluded by ‘noindex’ tag” message, then the noindex tag is doing its job.
(This is one of the few times you WANT to see a red error message in the GSC 🙂 )
Depending on your crawl budget, it can take a few days or weeks for Google to re-crawl the pages you don’t want indexed.
So I recommend checking the “Excluded” tab in the Coverage report to make sure your noindexed pages are getting removed from the index.
For example, certain posts at Backlinko have paginated comments.
And every single comments page has the original blog post on it.
If those pages got indexed by Google, we’d have duplicate content issues up the wazoo.
Which is why we add a noindex tag to every single one of those pages.
Note: You can also block search engine spiders from crawling the page altogether by blocking their individual crawlers in your robots.txt file.
Use Canonical URLs
Most pages that have duplicate content on them should get the ol’ no index tag added to them. Or have the duplicate content replaced with unique content.
Canonical URLs are perfect for pages that have very similar content on them… with minor differences between pages.
For example, let’s say you run an ecommerce site that sells hats.
And you have a product page set up just for cowboy hats.
Depending on how your site is set up, every size, color and variation can result in different URLs.
Not good.
Fortunately, you can use the canonical tag to let Google know that the vanilla version of your product page is the “main” one. And all the others are variations.
Do I think that setting up Schema directly helps your site’s SEO?
No.
In fact, our search engine ranking factors study found no correlation between Schema and first page rankings.
That said:
Using Schema CAN give some of your pages Rich Snippets.
And because Rich Snippets stand out in the SERPs, they can dramatically improve your organic click through rate.
Validate Your XML Sitemaps
If you run a huge site, it’s hard to keep track of all of the pages in your sitemap.
In fact, many sitemaps that I look at have pages with 404 and 301 status codes. Considering that the main goal of your sitemap is to show search engines all of your live pages, you want 100% of the links in your sitemap to point to live pages.
Even sites that are super mobile-friendly can run into issues.
And unless users start emailing you complaints, these issues can be hard to spot.
That is, unless you use the Google Search Console’s Mobile Usability report.
If Google finds that a page on your site isn’t optimized for mobile users, they’ll let you know.
They even give you the specific things that are wrong with the page.
That way, you know exactly what to fix.
Bonus Chapter:Technical SEO Case Studies
Let’s cap off this guide with a set of brand new technical SEO case studies.
Specifically, you’ll see how four Backlinko readers increased their Google rankings with:
Date Schema
Internal linking
FAQ Schema
Website migration best practices
So without further ado, let’s get right into the case studies.
Case Study #1 How Felix Used Internal Linking to Boost Organic Traffic By 250%
When Felix Norton audited one of his clients’ websites (an event hiring marketplace) for technical SEO issues, one thing stood out:
They weren’t using any internal links! And the internal links the site DID have didn’t use keyword-rich anchor text.
At this point, this client had been with Felix’s agency for 3 months. Felix and his team had been publishing A TON of high-quality content on their client’s blog. But traffic and rankings were stagnant.
Well, during that audit, Felix realized that none of this awesome content was linked together. Even worse: the content didn’t link to important product and services pages.
That’s when Felix decided to add internal links to their high-priority content pieces.
Product pages.
And pieces of related content.
Which resulted in a 250% traffic boost within a week of adding these strategic internal links.
Case Study #2 How Salman Used Date Schema to Double His Page’s Google Traffic
Backlinko reader Salman Baig runs a tech review site called Voxel Reviews.
One of Salman’s most important keywords is “Best Gaming Laptops under 500”.
But it’s a highly-specific keyword with high search intent. Which means that it was worth Salman’s time to find a way to increase the rankings for that term.
And when he looked at the SERPs for that keyword, he saw an opportunity. An opportunity that he could use technical SEO to tap into.
Specifically, he noticed that most of the pages on the first page had the current month and year in their title tag.
However, many of these pages weren’t actually updating the page (or the “published” date in their HTML).
For example, this page adds the current month to its title tag like clockwork.
But if you search for that page’s URL with a date range…
…you can see the actual date Google has saved for this article:
That was the opportunity that Salman saw:
Adding the current month to his title tag may help his organic CTR. But Google clearly ignores it.
But if Google could see that Salman’s page was legit updated, he might get a rankings boost.
And to show Google that his page was actually up-to-date, he added the date to the top of his post.
He also updated his Schema to update the “datePublished” and “dateModified” dates.
This change helped Salman’s site get picked up by a Featured Snippet.
That Featured Snippet, plus a rankings boost for his target keyword, increased traffic to that page by more than 200%.
Case Study #3 How Neil Reversed a Disastrous Website Migration
Neil Sheth’s SEO agency, Only Way Online, took on a new client who’s rankings had completely tanked.
As it turned out, the site migrated their website to the latest version of Magento.
They also decided to combine this migration with a handful of changes to their website (like removing URLs that were getting search traffic) without considering the impact on organic search.
The site went from about 30,000 monthly visitors to as low as 3,000 visitors a month in a span of 2 months.
And when Neil did a full SEO site audit to figure out what went wrong, he found a host of technical SEO issues like:
Pages without internal links pointing to them (orphan pages)
Pages that were canonicalizing themselves to noindex pages
Pages redirecting to a page that is then redirected to another page (redirect chains)
Broken internal and external links
Sitemap including pages that should not be indexed
Poorly-optimized title and description tags
And you can start to see an uptick in organic traffic in the weeks following these technical SEO fixes.
In fact, from July 2019 to October the site has increased organic traffic by 228%.
Case Study #4 How Bill Boosted His Clicks by 15.23% Using FAQ Schema